Let’s analyse a simple experiment. Suppose you throw a fair, six-sided dice and it lands with the side that says 4 facing up? What exactly is going on here, and how can we explain it using the language of mathematics? The throwing of a dice can be represented using a map, believe me, it can; for we are taking some object and we are mapping it to some other object are we not? In this case we are mapping the act of throwing a dice to the set of just six integers: . Now why would we want to do this? Because it is desirable to express, or relate things in terms of something more useful; more than often the first thing is some abstract object and the second thing is the real numbers. In mathematics we denote this map by the capital letter
. Now why would we want to do this? Because it is desirable to express, or relate things in terms of something more useful; more than often the first thing is some abstract object and the second thing is the real numbers. In mathematics we denote this map by the capital letter  and we call it a random variable.
and we call it a random variable.
Granted, random variables can, at first, be strange. Their job is to convert experiments to outcomes; events that are completely random to solid, predictable numbers. In general, due to the shear number of possible experiments one can conjure up, it should be clear that we need a set of numbers of infinite size to map them to. Hence why we define random variables as maps from events and experiments to the set of real numbers 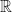 . In symbols we write
. In symbols we write 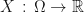 . Note that we have symbolised all possible events that could occur by the single Greek letter
. Note that we have symbolised all possible events that could occur by the single Greek letter  . This is called the sample space and you have to think of it as a collection of possible outcomes, not all outcomes, no that would be incorrect. It is the set of all possible outcomes of some experiment. A random variable completely ignores impossible outcomes when it chooses to map you to a real number.
. This is called the sample space and you have to think of it as a collection of possible outcomes, not all outcomes, no that would be incorrect. It is the set of all possible outcomes of some experiment. A random variable completely ignores impossible outcomes when it chooses to map you to a real number.
Unfortunately you can’t just pick out any old map and declare that it is a random variable. So we now have to delve a little deeper in to the realm of Measure Theory in order to completely explain random variables. Of course you can just stop here if you are happy with the concept, and in most courses this is as far as the definition needs to go.
Admissible Random Variables
For a map to truly be a random variable it must be possible to compute the probability of the outcome that the random variable is mapping. In other words, take some outcome  from the sample space,
from the sample space,  , if the map
, if the map 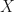 is to be a random variable you must be able to compute the probability of that outcome from occurring,
is to be a random variable you must be able to compute the probability of that outcome from occurring,  .
.
The probability of an outcome is yet another map, a much more stringent map, that takes an outcome of some experiment and maps it to a the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=%23111111&s=0&c=20201002) . Before you get confused, yes we have two maps now. The probability mapping is a function of an event or outcome, thus we talk about the probability of some event and we write it like this:
. Before you get confused, yes we have two maps now. The probability mapping is a function of an event or outcome, thus we talk about the probability of some event and we write it like this:  . This map always returns a number between zero and one, furthermore it always (by definition) returns 1 if the outcome is the entire sample space ; and returns 0 if the outcome is the empty set
. This map always returns a number between zero and one, furthermore it always (by definition) returns 1 if the outcome is the entire sample space ; and returns 0 if the outcome is the empty set 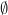 . The probability map
. The probability map  must also satisfy what is called the countable additivity property that for all countable (can be numbered with positive integers) collections of pairwise disjoint (non-coincidental) outcomes the probability of all of them is precisely the same as the sum of the probability of each one seperately; indeed when it comes to probabilities the whole is exactly the sum of its parts. Technically the probability map is a functional (so is a random variable) and its proper name is a probability measure simply because it allows us to measure events in a logical way.
must also satisfy what is called the countable additivity property that for all countable (can be numbered with positive integers) collections of pairwise disjoint (non-coincidental) outcomes the probability of all of them is precisely the same as the sum of the probability of each one seperately; indeed when it comes to probabilities the whole is exactly the sum of its parts. Technically the probability map is a functional (so is a random variable) and its proper name is a probability measure simply because it allows us to measure events in a logical way.
The next issue one encounters in a study of random variables is that in some cases the number of possible outcomes of some experiment can become so convoluted and enormous that it becomes an impossible task to map them to the real numbers. We want to exclude all possible paradoxical experiments (see the Banach-Tarski paradox) so we have to somehow, limit or reduce the number of outcomes of an experiment to a nice number so that the random variable can map each and every one, in a nice calm way, to the set of real numbers. We do this by imposing a sigma-algebra.
