
Introduction
In this blog we will be looking at the Recipe for Pricing.
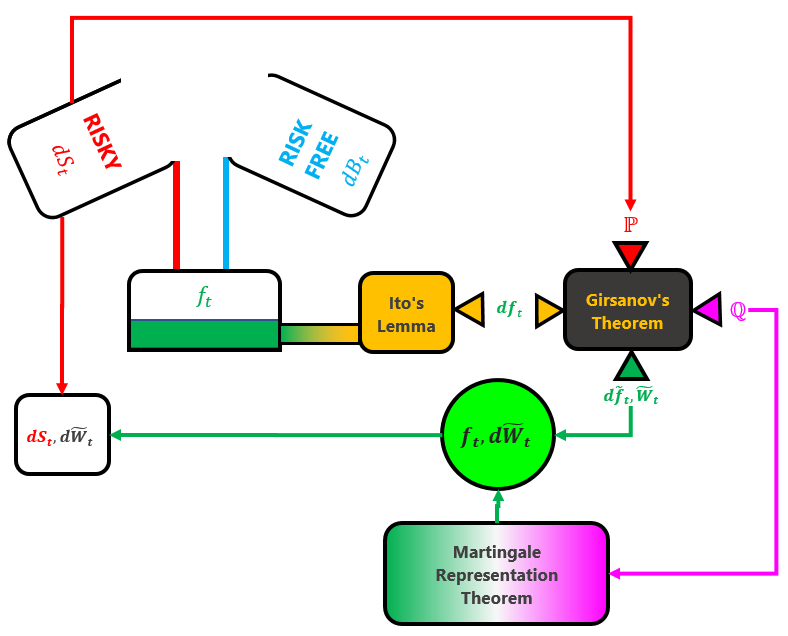
The recipe involves starting by mixing together a risky asset and a risk-free asset. Then we take that mixture and feed it into the Ito’s Lemma machine. Out of that machine pops the stochastic differential equation for the mixture. Then we throw that mixture in the Girsanov oven, together with the original real-world probability measure 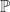
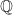
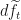

With these cooked ingredients we then cool it by placing it in the Martingale Representation Theorem. When it is cooled thoroughly, the cooked mixture reduces to 

So let’s see how this recipe works.
The Black-Scholes Pricing Framework
Risky assets are assets whose value changes randomly. From one instant to the next its price might move up some amount, or down some amount. It could even stay the same. The direction and the amount of movement is random.
So how do we price such risky assets?
Well, we need to introduce some assumptions. Different sets of assumptions define different so-called pricing frameworks. One very popular framework is the Black-Scholes (BS) pricing framework (also known as the Black-Scholes Model), but there are others. Under the BS framework there are 7 assumptions. We won’t go in to them here suffice to point out that one of the assumptions is: the log return of a risky asset price is a random walk with drift. Another way to say this is: risky asset prices follow a geometric Brownian motion.
It turns out that this is a pretty good assumption because GBMs exhibit quite a few similarities with what is observed in real life. For example, and this one is fairly simple: a GBM only assumes positive values, just like real (risky) stock prices! Another similarity is that the amount of ‘roughness‘ as seen in the graph of a GBM is about the same amount of ‘roughness‘ as seen in the graph of a risky stock price.
However, GBMs are not a perfect replication of reality. For example, the volatility of risky stock prices in real life changes over time, even randomly. But the volatility of a GBM is constant over time. Moreover, real life stock prices exhibit jumps caused by unpredictable events, but GBMs are continuous.
Never-the-less the Black-Scholes model is a very popular model in quantitative finance and can be used to accurately predict the price of a risky (random) asset; and in this article we will see just how this is done in practice.
First of all, we must operate under the so-called Black-Scholes-Merton framework (or the BSM model). We certainly don’t have to use the BSM model and, in fact, there are a great many other frameworks we could use. Some frameworks (like the Black-76 framework) contains different assumptions that might better suit some other risky asset that refuses to play by the rules of the Black-Scholes framework (for example, commodity futures). But there are risky assets which do play by the Black-Scholes-Merton rules quite well, and it is these which we will focus our attention on in this article.
The BSM Model assumes that the price of a risky asset follows a geometric Brown motion with drift. This means that the change in price of risky assets is equal to some amount of drift (up or down) plus some amount of randomness (the size of the up or down movement). The combination of the drift and the amount of randomness can be captured, or represented, by the following equation:
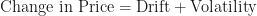
But what good is knowing the change of the price? Isn’t it better to know what the actual price is?
That’s a good question, but defining actual prices is a little too specific. We would prefer a generalised approach to pricing and not tie ourselves to any sort of value magnitude or type (like different currencies). You see, a change in price is a dimensionless ratio and is much easier to manipulate and apply to an asset (like, simply multiplying it). Plus, using some sophisticated tools, we will be able to convert a change in price to an actual price anyway.
Let’s put some standard mathematical symbols to our heuristic equation above. I have coloured this equation red to indicate that it is for the risky asset:
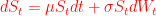
Here, 

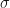
Sometimes you’ll see this equation written divided through by the spot price
but the former is more common, mostly to indicate its geometric property.
This equation looks like your typical differenial equation except for that 
As mentioned before, the rate of change of the price of the risky asset 
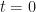
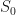
It is very difficult to take a randomly evolving thing and create something specific (like an actual price) from it. But it turns out we can with the help of a few mathematical tools and another asset: the risk-free asset.
By incorporating a risk-free asset in with a risky asset to annihilate randomness was a key insight in to the Black-Scholes-Merton framework of 1973.
So the theme for the rest of the article is to derive an actual price
What else do we need to assume?
The next assumption we need from the BSM model to be able to make any progress in our quest is the one that states that the rate of return of a risk-free asset is constant, a reasonable assumption. This has a stochastic differential equation representation too, and I’ve coloured this one blue to indicate that it is risk free:
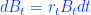
Where 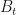
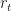
As it turns out, by defining such an object in the BSM model, allows us to discount the risky asset price from any future time
![\displaystyle\text{Discounted Value} := \int_0^T e^{-\lambda t}\left[\text{Future Value}\right]dt](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Ctext%7BDiscounted+Value%7D+%3A%3D+%5Cint_0%5ET+e%5E%7B-%5Clambda+t%7D%5Cleft%5B%5Ctext%7BFuture+Value%7D%5Cright%5Ddt+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Continuous discounting and the exponential
Why is continuous discounting represented by the exponential 
Suppose you begin with 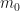
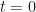

One thing you could do is to divide that length of time up in to smaller pieces (a method known as discretisation), each with a length of time 
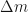
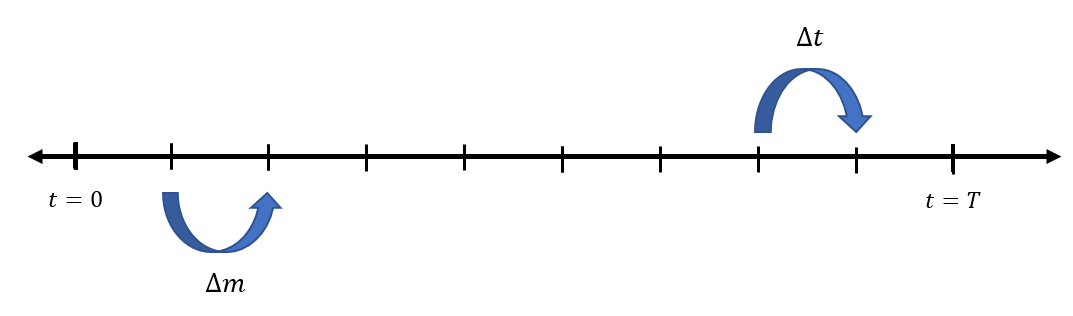
How many small intervals of
What interest rates do, is this: they create a change in money amount 

Thus, an initial amount of money 

which equals

factoring out the initial amount of money

Then, for each little time step 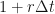

Since multiplication commutes, this means that for
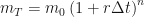
We already know what

Now we need to un-discretise time, and the way we do this is to apply the limit as 

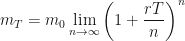
If we make the substitution 
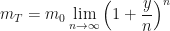
and then a second substitution 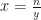
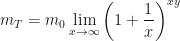
then using the property of exponents to split the exponent up, we get
![\displaystyle m_T = m_0 \lim_{x\rightarrow\infty} \left[\left(1+ \frac{1}{x}\right)^{x}\right]^{y}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+m_T+%3D+m_0+%5Clim_%7Bx%5Crightarrow%5Cinfty%7D+%5Cleft%5B%5Cleft%281%2B+%5Cfrac%7B1%7D%7Bx%7D%5Cright%29%5E%7Bx%7D%5Cright%5D%5E%7By%7D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
and now, the part in brackets – together with the limit, is well-known to be 
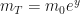
Finally, we need to reverse our subsitutions:

as required.
Combining a Risky Asset with Risk-a Free Asset
By continuously discounting at the risk-free interest rate we have essentially defined a new function 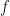

As written, this function is also random and contains drift (both properties of risky things) because it contains a factor of
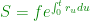
as this gives us no information because the right-hand side still contains
As before, let’s look at the change in 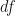
It’s difficult to take the derivative of a random function. But luckily we can use Itô’s Lemma (which is basically the random, stochastic version of the chain rule) to perform the mapping
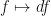
So let’s look at how we do that…
Practical Itô’s Lemma
Once you have a composite function like 
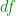
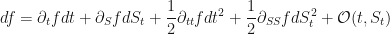
which is really just a sum of four parts and is derived from the Taylor series expansion of
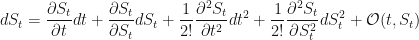
Both of these expansions are worth memorising if you are going to be doing a lot of these kinds of calculations.
But now we have to do some maths…
1st Part
The first part involves the calculation of the partial derivative of 
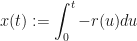
Then, recalling the fundamental theorem of calculus, we immediately have that
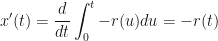
which will be a useful result for us in just a second.
Right, let’s jump in and perform this partial derivative. The only explicit 

2nd Part
The second part is much easier. We just take the partial derivative of

3rd Part
The third part is always trivial because
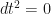
4th Part
The final and fourth part involves calculation of the second partial derivative of
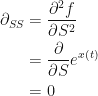
Combining Parts for Ito’s Lemma
This gives:

Now we need to substitute back in our original equation for
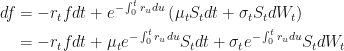
We can’t go any further until we rearrange 
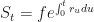
and notice that the negative exponent has now become a positive one. Now,
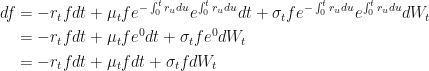
and, collecting like terms to factor out the 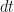
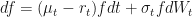
Rearrange to get dW Alone
The next step, is to get the above equation in to the right form.
Think about what we are going to do next: we are going to use Girsanov’s theorem to make an argument about 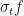

and now the
Using Girsanov’s Theorem
Finding Lambda
Girsanov’s theorem is a theorem about 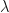
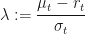
What about the
Well, it’s not really about the pieces common to both. The parameter
So, once we have found lambda we can implement Girsanov’s Theorem. How do we do that?
Well, it is pretty much just writing down the same paragraph. Every time you do this step, you’ll be stating the same thing over and over again without ever changing anything, so it is worth memorising it. I have, and now I know that when I get to this stage, I just blurt it out, word-for-word, without thinking. It’s needed though, and it’s important, because you can’t proceed to the next step unless you have clearly stated it. So let’s do it:
By Girsanov’s Theorem there exists an equivalent martingale measure (EMM)
defined by the Radon-Nikodym derivative
such that under the measure
is a
or,
…by differentiating both sides with respect to
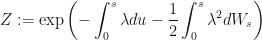

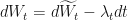
That’s it. This theorem only requires that we have defined precisely what
The Martingale Representation Theorem
Now that we have been handed the new Wiener process
Ultimately, we have a stochastic process 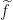
The martingale representation theorem comes to the rescue, because it provides the stochastic process
OK, so what do we have? Our stochastic process (under
This is certainly not driftless. Just look at that almighty drift as the coeffcient of the
OK, let’s see what this stochastic process looks like under 
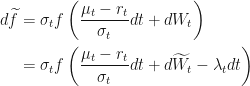
Let’s throw in what 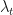

The lambda’s cancel out, and we are left with:

which is driftless! … no
We then define
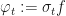
…to be the coefficient, which we will use in the next step.
OK, so now we have a driftless stochastic process, albeit, one under the measure
Under the
is driftless, then by the Martingale Representation Theorem there exists a
, adapted to the filtration

OK, so we take that formula, and plug in our value for
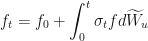
Final Step
In the final step, we take Girsanov’s Theorem results:
and substitute it in to the original stochastic differential equation:

to get:

…and we are done!
We have successfully mixed the risky asset 
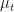
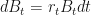
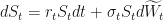
Under the risk-neutral probability measure
Conclusion
In this blog, we considered a market consisting of just one risky asset and one risk-free asset. We assumed that the price dynamics of these two assets were driven by stochastic differential equations: the risky one by a Wiener process, and the risk-free one by a deterministic ordinary differential equation.
We then formed a new stochastic differential equation by continuously discounting the risky one by the risk-free rate. This new process was not a martingale under the original measure, because when we used Ito’s lemma to find the price dynamics of the new process, we found that it had huge amounts of drift: this huge amount we called the market price of risk.
Then we implemented Girsanov’s theorem to find a new probability measure such that the discounted price process is a martingale.
And finally, we found an equivalent risky asset price process, under the new probability measure, that was indeed a martingale again under the new measure.
If the risky asset is, say, the price of stock, then what we have just shown is that the discounted stock price is a martingale under the risk-neutral measure.
This allowed us to find a probability measure and Wiener process such that the drift is replaced by the risk-free interest rate.
The Recipe
- Define a risky stochastic process,
- Define a risk-free stochastic process,
- Form some function or composition of the two:
- Use Ito’s product, or quotient lemma to find
- Rearrange and factor stuff to get
- Note the coefficient of
- Implement Girsanov’s theorem and insert
. Get
- State the results of Girsanov’s theorem, get
- Differentiate w.r.t.
- Form a new stochastic process under
- Implement the Martingale Representation Theorem. State equation of
- Substitute
References
- Itô, Kiyosi, “Stochastic Integral” Proc. Imperial Acad. Tokyo 20, 519-524, (1944)
- http://mathmistakes.info/facts/CalculusFacts/learn/doi/doi.html

That’s interesting but too complex to understand 🙂
This is amazing!
Excellent! Just one thing. I read it somewhere that it is the property of the brownian process that is it martingale. What does it mean? How it is realated to the new dSt we computed in the end. Thanks!
I like the way you explain complex concepts to people like me who have difficulties understanding mathematical notation.