The conditional expectation is a property associated with a random variable that tells you the likelihood of some event given some other event has already occurred. Before we can discuss this we need to cover some basic definitions first. As always we begin with a probability space  consisting of the sample space of all events and outcomes
consisting of the sample space of all events and outcomes  , the sigma-algebra of possible/measurable events
, the sigma-algebra of possible/measurable events  , and a probability measure that assigns a real number from the unit interval
, and a probability measure that assigns a real number from the unit interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=%23111111&s=0&c=20201002) to each event
to each event  from the sigma-algebra. This is elementary stuff. Next we introduce the conditional probability measure as being a functional of some certain event that has already occurred
from the sigma-algebra. This is elementary stuff. Next we introduce the conditional probability measure as being a functional of some certain event that has already occurred  (such that
(such that  ), and another event whose probability we wish to measure. The first thing to understand is that the probability that some event will occur can be very much different to the probability that the same event will occur given that some other event has already occurred. This is because the conditional probability measure
), and another event whose probability we wish to measure. The first thing to understand is that the probability that some event will occur can be very much different to the probability that the same event will occur given that some other event has already occurred. This is because the conditional probability measure  (as opposed to the ordinary probability measure
(as opposed to the ordinary probability measure  ) actually removes the event that has already occurred from the sample space and re-assigns all the probabilities to the remaining to-be-determined events. It is an entirely new measure.
) actually removes the event that has already occurred from the sample space and re-assigns all the probabilities to the remaining to-be-determined events. It is an entirely new measure.
DEFINITION: Conditional Probability Measure
Let 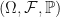 be a probability space and let
be a probability space and let  be an event that has already occurred with probability one. Then the functional defined by
be an event that has already occurred with probability one. Then the functional defined by

is called a conditional probability measure.
Partitions
The next ingredient we need is that of a partition, which is simply the act of splitting up a set in to smaller subsets  . These smaller subsets are called blocks and they satisfy the property that they never overlap, which means that their intersection is empty:
. These smaller subsets are called blocks and they satisfy the property that they never overlap, which means that their intersection is empty:  ; and if you stick all of them together you end up reconstructing the whole set that you began with, which means that their union is the whole set:
; and if you stick all of them together you end up reconstructing the whole set that you began with, which means that their union is the whole set:  . We say that one can partition a set in to a collection
. We say that one can partition a set in to a collection  of smaller blocks who are each collectively exhaustive and mutually exclusive with respect to the set being partitioned. There is no mathematical trickery going on here, we are simply breaking up the set, which can be done in a number of different ways, but more importantly, can always be done.
of smaller blocks who are each collectively exhaustive and mutually exclusive with respect to the set being partitioned. There is no mathematical trickery going on here, we are simply breaking up the set, which can be done in a number of different ways, but more importantly, can always be done.
Now why are we interested in partitioning a set? Well, if the set to be partitioned is the sample space then we should be very interested because if you think about what a random variable does: it maps events (subsets of the sample space) to the real numbers, and now think about the inverse of a random variable: it maps a real number to the sample space (to the sigma-algebra really, but what goes in to the sigma-algebra always goes in to the sample space). Then, thinking about that some more, we can imagine that, depending on the random variable mapping, the same real number may get mapped to the same subsets, so you have various subsets of the sample space with the same number associated to them by the inverse random variable. If you cut up the sample space by these numbers you are partitioning it! Kind of like painting by numbers. Said another way: A random variable naturally partitions the sample space. Let’s see exactly why this is the case.
Refinements
Okay, so we are focusing on discrete probability theory here, and in particular discrete random variables. We have at our disposal the idea of partitioning a set, or the sample space, in to a collection of blocks. We’ve also hinted that in some way, a random variable partitions the sample space as well. Before we can prove that we need to introduce a very special kind of partition: a refinemnet.
DEFINITION: Refinement
Let be a partition of a set . Then a partition 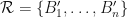 is called a refinement of if each block
is called a refinement of if each block 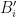 of
of  is contained in some block
is contained in some block  of , such that
of , such that  . We denote such a refinement this by
. We denote such a refinement this by  .
.
We will need this concept of a refinement when it comes time to prove the connection between random variables naturally inducing a partition on the sample space and it’s measurability.
Random Variables and Natural Partitions
Consider a (discrete) random variable  , recall that it maps events (or subsets of the sample space) from the sigma-algebra to the real numbers. Think of all the real numbers
, recall that it maps events (or subsets of the sample space) from the sigma-algebra to the real numbers. Think of all the real numbers  that the random variable might map to. Collect these together and form a set
that the random variable might map to. Collect these together and form a set  , this is called the image of the random variable – it is a collection of all the points where the random variable mapping sends events and subsets to. We denote this by
, this is called the image of the random variable – it is a collection of all the points where the random variable mapping sends events and subsets to. We denote this by  . Now, the inverse random variable
. Now, the inverse random variable 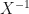 goes backward and maps a real number to a subset of the sample space . If we know the random variable then we know its image
goes backward and maps a real number to a subset of the sample space . If we know the random variable then we know its image  , then all we need to do is follow the real numbers back via the inverse random variable and see what subset of the sample space we end up in. Then, as you would with paint-by-numbers, we partition the sample space using those numbers. That is, we naturally partition
, then all we need to do is follow the real numbers back via the inverse random variable and see what subset of the sample space we end up in. Then, as you would with paint-by-numbers, we partition the sample space using those numbers. That is, we naturally partition  the sample space using the inverse random variable, or by partitioning using the inverse image of the elements from . In symbols:
the sample space using the inverse random variable, or by partitioning using the inverse image of the elements from . In symbols: 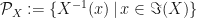 .
.
Measurable Random Variables
If you begin with a probability space (a sample space, a sigma-algebra of events, and a measure functional) and introduce a random variable as a mapping from the sigma-algebra to the real numbers, how do you say that the random variable is measurable? After all, the measure functional that comes equipped with the probability space measures probabilities of events, not random variables. But, with the help of partitions and refinements, we can measure a random variable. Here’s how we do it:
We take a probability space and any random variable . We then form a partition of the sample space in to the one induced naturally by the random variable. Since the blocks of the partition have the exact same real number mapped to them by the inverse random variable, we know for sure that the random variable is constant on each block. In other words, the random variable is constant on each block precisely because we partitioned the blocks using the inverse random variable. If we used some other partition then it would no longer be constant. Now we define it:
DEFINITION: Random Variable Measurability
Let be the partition of the sample space . A random variable is said to be 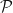 -measurable if the random variable is constant on each block of the partition .
-measurable if the random variable is constant on each block of the partition .
Could the same random variable might be considered measurable given some other partition and not the natural one? Maybe. It depends on whether or not the partition is a refinement of the natural partition.
THEOREM
A random variable is said to be  -measurable if and only if is a refinement of the natural partition .
-measurable if and only if is a refinement of the natural partition .
What About Infinite Sample Spaces?
We have seen so far that for finite sample spaces, partitions are intimately connected with random variables via their inverse images. As it happens, the notion of a partition does not generalise readily for infinite sample spaces. Instead we use an algebra.
Recall that an algebra 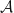 is a collection of subsets of some larger set such that the empty set is in the collection, it’s closed under complements, and under unions. Now, just as a random variable can naturally define a partition of the sample space, it can also define a natural algebra
is a collection of subsets of some larger set such that the empty set is in the collection, it’s closed under complements, and under unions. Now, just as a random variable can naturally define a partition of the sample space, it can also define a natural algebra  consisting, again, of inverse images. Now let us re-define the measurability of a random variable to one with respect to an algebra instead of a partition. In fact, it comes as no surprise that for a random variable to be algebra-measurable (instead of partition-measurable) we want it to be constant on all elements of the algebra.
consisting, again, of inverse images. Now let us re-define the measurability of a random variable to one with respect to an algebra instead of a partition. In fact, it comes as no surprise that for a random variable to be algebra-measurable (instead of partition-measurable) we want it to be constant on all elements of the algebra.
DEFINITION: Measurability of Random Variables
Let be a random variable on a sample space . Let be some algebra of subsets on . Then the random variable is -measurable if is equal to some constant  on all elements of the algebra, or:
on all elements of the algebra, or:

Continuing in the same fashion as before, we can say that any random variable is measurable with respect to any algebra so long as the algebra is (not a refinement) but simply a subset of the algebra naturally induced by the random variable:
Finally, Conditional Expectation!
We are now ready to formulate the definition of conditional expectation: We just take the ordinary expectation of a random variable of an event , but now we do it using the conditional probability measure , where is some certain event that has already occurred. Thus,
DEFINITION: Conditional Expectation
Let  be a probability space and let be an event which has or could potentially occur. Then the conditional expectation (using the ordinary probability measure that comes equipped with the probability space) of a random variable
be a probability space and let be an event which has or could potentially occur. Then the conditional expectation (using the ordinary probability measure that comes equipped with the probability space) of a random variable ![\mathbb{E}^{\mathbb{P}}[X|A]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5BX%7CA%5D+&bg=ffffff&fg=%23111111&s=0&c=20201002) equals the expectation (using the new conditional probability measure ) of just the random variable with no conditioning. In symbols:
equals the expectation (using the new conditional probability measure ) of just the random variable with no conditioning. In symbols:
![\mathbb{E}^{\mathbb{P}}[X|A] = \mathbb{E}^{\mathbb{P}_A}[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5BX%7CA%5D+%3D+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D_A%7D%5BX%5D+&bg=ffffff&fg=%23111111&s=0&c=20201002)
If we use the indicator function  , which returns 1 when it eats a subset of and a 0 when it eats something which is not, and we use it on the random variable , we get the product
, which returns 1 when it eats a subset of and a 0 when it eats something which is not, and we use it on the random variable , we get the product 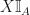 which essentially forces the random variable to only act on subsets of the specified subset (the result otherwise is zero which, in probability terms, is precisely the same as an impossible event). Thus the product can be viewed in terms of set operations as
which essentially forces the random variable to only act on subsets of the specified subset (the result otherwise is zero which, in probability terms, is precisely the same as an impossible event). Thus the product can be viewed in terms of set operations as 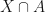 – this is clear abuse of notation as is not a set, hence why we need the indicator function to do the same thing as set inclusion. Using the ordinary probability measure , we can take the ordinary expectation of this
– this is clear abuse of notation as is not a set, hence why we need the indicator function to do the same thing as set inclusion. Using the ordinary probability measure , we can take the ordinary expectation of this ![\mathbb{E}^{\mathbb{P}}[X\mathbb{I}_A]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5BX%5Cmathbb%7BI%7D_A%5D+&bg=ffffff&fg=%23111111&s=0&c=20201002) and then divide this number (remember that the expectation operator
and then divide this number (remember that the expectation operator 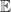 is a functional which assigns real numbers to events) by the probability of the event occurring and we get another representation of the conditional expectation that really lines up with the representation of the conditional probability measure introduced at the beginning of this article:
is a functional which assigns real numbers to events) by the probability of the event occurring and we get another representation of the conditional expectation that really lines up with the representation of the conditional probability measure introduced at the beginning of this article:
LEMMA: Conditional Expectation
Given a probability space, a random variable and an event that has or could occur, then the conditional expectation of 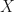 with respect to the event can be expressed as
with respect to the event can be expressed as
![\mathbb{E}^{\mathbb{P}}[X|A] = \frac{\mathbb{E}^{\mathbb{P}_A}[X\mathbb{I}_A]}{\mathbb{P}(A)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5BX%7CA%5D+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D_A%7D%5BX%5Cmathbb%7BI%7D_A%5D%7D%7B%5Cmathbb%7BP%7D%28A%29%7D+&bg=ffffff&fg=%23111111&s=0&c=20201002)
