
Today at work we were discussing the concept of Expected Shortfall as a risk measure and how it is computed. Expected shortfall (or ES), in the context of financial risk, is similar to Value at Risk (or VaR) except that one is usually asked to consider the average of a range of values rather than a single percentile, as is done for VaR. This makes the risk measure more robust as it requires perfect calculation of every value in the tail of the distribution whereas VaR essentially ignores those values.
In most cases a computer is calculating these values, usually about ten thousand or so for VaR on any given day, and so we tend to have a finite number of values to either take a percentile or to take an average.
But what if we have an infinite number of values?
In the case of an infinity of numbers, the average becomes a (Riemann) integral. See my previous article on this concept here. Hence, the expected shortfall of a range of values becomes an integral. Since those values can each be considered as an infinite number of VaR numbers at some percentile (just separated by an infinitesimal percentile), we can say that the expected shortfall is the integral of 
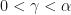


Where the Value-at-Risk is defined as

which in words says:
The
-percentile VaR is defined as the smallest real value
such that the probability of exceeding
.
Alternatively, we could define the probability distribution of losses as 
Where does the Laplace transform fit in to this?
Well, we could just define the Laplace transform to be precisely the expectation of 
 := \mathbb{E}\left[e^{-sX}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D%5Bf%5D%28s%29+%3A%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7B-sX%7D%5Cright%5D+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
but this doesn’t explain much.
So let’s go back one step and take a look at the Expected Value a little more closely.
In our case, which is probability theory, the expected value of a random variable
![\displaystyle \mathbb{E}[X] := \sum_{i=1}^k x_i p_i = x_1 p_1 + x_2 p_2 + \cdots + x_k p_k](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BX%5D+%3A%3D+%5Csum_%7Bi%3D1%7D%5Ek+x_i+p_i+%3D+x_1+p_1+%2B+x_2+p_2+%2B+%5Ccdots+%2B+x_k+p_k&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
We’ve already discussed that when we have an infinite of these numbers, i.e. when 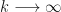

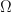

Hence, our requirements to construct and evaluate such an integral (expectation) of random variables is a
- Sample space
- Sigma-algebra of events
- Probability measure
collectively known as a probability space 
Once we have this we can easily define the expectation of a random variable as
![\displaystyle \mathbb{E}^{\mathbb{P}}[X] := \int_{\mathbb{R}} xf(x)\textup{d}x](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5BX%5D+%3A%3D+%5Cint_%7B%5Cmathbb%7BR%7D%7D+xf%28x%29%5Ctextup%7Bd%7Dx&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Which is very similar to the definition above involving the summation.
Now all we need to do is consider taking the expectation of the exponential of the random variable, i.e. what is ![\mathbb{E}\left[ e^{-X}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+e%5E%7B-X%7D%5Cright%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Well, this is very similar to the moment generating function (MGF) of
![M_X (s) := \mathbb{E}\left[e^{sX} \right],\quad\quad\forall\, s \in \mathbb{R}](https://s0.wp.com/latex.php?latex=M_X+%28s%29+%3A%3D+%5Cmathbb%7BE%7D%5Cleft%5Be%5E%7BsX%7D+%5Cright%5D%2C%5Cquad%5Cquad%5Cforall%5C%2C+s+%5Cin+%5Cmathbb%7BR%7D+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Note the positive exponential.
The key benefit of the MGF is that you can Taylor expand it as
![\displaystyle M_X(s) := \mathbb{E}\left[ e^{sX}\right] = 1 + s\mathbb{E}[X] + \frac{s^2}{2!}\mathbb{E}[X^2] + \frac{s^3}{3!}\mathbb{E}[X^3] + \cdots + \frac{s^n}{n!}\mathbb{E}[X^n] + \cdots](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X%28s%29+%3A%3D+%5Cmathbb%7BE%7D%5Cleft%5B+e%5E%7BsX%7D%5Cright%5D+%3D+1+%2B+s%5Cmathbb%7BE%7D%5BX%5D+%2B+%5Cfrac%7Bs%5E2%7D%7B2%21%7D%5Cmathbb%7BE%7D%5BX%5E2%5D+%2B+%5Cfrac%7Bs%5E3%7D%7B3%21%7D%5Cmathbb%7BE%7D%5BX%5E3%5D+%2B+%5Ccdots+%2B+%5Cfrac%7Bs%5En%7D%7Bn%21%7D%5Cmathbb%7BE%7D%5BX%5En%5D+%2B+%5Ccdots+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
from which you can define the random variable’s moments. However, the drawback is that this infinite series may not converge since the infinite integral of a positive exponential can indeed blow up.
Therefore, we change the variable 
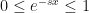
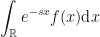
always converges. We define the above integral as the Laplace transform of
Starting with the basic definition of an expectation we can extend the definition to random variables via the introduction of a Lebesgue integral (which carries with it the requirements of a probability space). The expectation is therefore an infinite integral. We can apply an exponential transformation 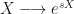

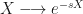
 := \mathbb{E}^{\mathbb{P}}\left[e^{-sX}\right] = \int_{\mathbb{R}} e^{-sx} f_X(x)\textup{d}x](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BL%7D%5Bf%5D%28s%29+%3A%3D+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5Cleft%5Be%5E%7B-sX%7D%5Cright%5D+%3D+%5Cint_%7B%5Cmathbb%7BR%7D%7D+e%5E%7B-sx%7D+f_X%28x%29%5Ctextup%7Bd%7Dx+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
This definition requires
- A probability space
,
- particularly because the probability measure
allows us to form the Lebesgue integral,
- A probability density
of the random variable must exist.
Therefore, given a random variable 
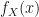
](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D%5Bf_X%5D%28s%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)


Why would we want this?
The power of the Laplace transform in this setting is in its ability to produce the cumulative distribution function (CDF) 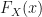
The Laplace transform finds the CDF in the transformed variable 
![\displaystyle F_X(x) = \mathcal{L}^{-1}\left[ \frac{1}{s} \mathbb{E}^{\mathbb{P}}\left[ e^{-sX} \right] \right](x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X%28x%29+%3D+%5Cmathcal%7BL%7D%5E%7B-1%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bs%7D+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5Cleft%5B+e%5E%7B-sX%7D+%5Cright%5D+%5Cright%5D%28x%29&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Now going back to risk measures (and the topic of this discussion) the expected shortfall is defined as
![\displaystyle \textup{ES}_{\alpha}(X) := \mathbb{E}^{\mathbb{P}}[ -X\,:\, X \leq \textup{VaR}_{\alpha}[X]] = -\frac{1}{\alpha}\int_0^{\alpha} \textup{VaR}_{\gamma}(X)\textup{d}\gamma](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctextup%7BES%7D_%7B%5Calpha%7D%28X%29+%3A%3D+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5B+-X%5C%2C%3A%5C%2C+X+%5Cleq+%5Ctextup%7BVaR%7D_%7B%5Calpha%7D%5BX%5D%5D+%3D+-%5Cfrac%7B1%7D%7B%5Calpha%7D%5Cint_0%5E%7B%5Calpha%7D+%5Ctextup%7BVaR%7D_%7B%5Cgamma%7D%28X%29%5Ctextup%7Bd%7D%5Cgamma&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
The right-hand side of this expression can be re-written in terms of the probability density:
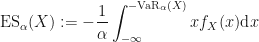
Practical Application
Often one has a portfolio loss function 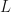

Further, the loss density 
Oftentimes the loss density is discrete and only takes on a finite number of values (usually as a result of a Monte Carlo) and so the CDF (which we want) is often some ugly discontinuous function.
The CDF can be approximated by the Laplace transform of the loss function:
![\displaystyle \mathbb{E}^{\mathbb{P}}\left[ e^{-sL} \right] = \int_0^{\infty} e^{-sx} f_L(x) \textup{d}x = \mathcal{L}[L](x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5E%7B%5Cmathbb%7BP%7D%7D%5Cleft%5B+e%5E%7B-sL%7D+%5Cright%5D+%3D+%5Cint_0%5E%7B%5Cinfty%7D+e%5E%7B-sx%7D+f_L%28x%29+%5Ctextup%7Bd%7Dx+%3D+%5Cmathcal%7BL%7D%5BL%5D%28x%29+&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
Summary
Thus, knowledge of the loss function can result in knowledge of the CDF via a Laplace transform. The CDF gives us all the Value-at-Risk numbers that we need which, in turn, provides us with the Expected Shortfall number.
Expected shortfall requires calculation of VaR at all loss thresholds. VaR requires knowledge of the cumulative distribution function of the loss density. One obtains the CDF by taking the Laplace transform of the loss density.
References
[1] J. J. Masdemont & L. Ortiz-Gracia, Haar wavelets-based approach for quantifying credit portfolio losses, arXiv:0904.4620, q-fin.RM.
