
In the previous blog we discussed the Recipe for Pricing. This recipe is a standard way to mix together two stochastic differentials 
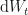
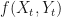
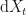

Recap

As discussed previously, we do this by introducing bias in to the source of the randomness. The bias carries away the drift from the diffusion, and has the equivalent effect of changing the probability measure from, say, a real-world measure 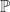
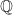
However, to do this we need a degree of freedom. This comes from the mixing of a risky asset with a risk-free asset.
How? Well, here is such a risk-free asset:
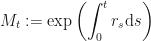
This is the money-market account, or a savings account which earns interest at some non-random (risk-free) interest rate 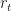

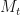

By taking this quotient, we have mixed a risky asset with a risk-free asset, and we can write this operation as a function:
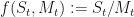
In the previous article on this subject, we discussed why it is just these two variables (a risky asset, and a risk-free asset) and no others that makes this magic happen; and this does indeed come from the assumptions of the Black-Scholes-Merton (BSM) model that we are working in. In other words, the BSM model describes the evolution of two assets. For example: this savings account
The way in which these two SDE’s are mixed together is three-fold:
- through the assumption that we express the risky asset price as a quotient
- Ito’s lemma – which is a fancy way of expanding SDE’s as a Taylor series, and
- by making some assumptions about:
- how the second partial derivative of time is basically zero,
- about how Wiener processes square in to time, and
- about how we include the first and second order terms and can ignore any other terms of higher order.
Ito’s lemma takes a risky 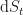
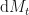

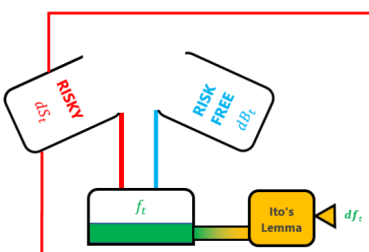
Diagram 1 – Ito’s Lemma produces the
Next, we take this Ito SDE

Diagram 2 – Girsanov’s theorem takes in a Taylor-esque, mixed stochastic process 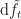
This theorem provides:
- a brand new SDE
(watch the tilde!),
- a new probability measure
- an adjusted Wiener process
on
But there is one major caveat: the new SDE
That’s right, Girsanov’s theorem only gives you the equivalent measure
But, by making a few algebraic manipulations we can invoke the Martingale Representation Theorem (MRT) to build a third, and final, equivalent SDE

Diagram 3 – The Martingale Representation Theorem outputs the Wiener differential 
This ends the recap. So that in this article we are going to use the recipe again, but this time with a different mixture.
The New Mixture
Recall that last time we mixed a risky asset,

and a risk-free asset,

by only extracting the risk-free rate 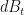

to form the mixing equation:

This time, however, we will form a linear mixture of the two. I.e., by mixing together 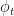
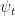
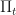

Let’s stop to think about this for a second.
Why would we want to use the Recipe for Pricing on an additive amount of risky and risk-free positions? Last time, we took the quotient, now we are taking the sum? The quotient allowed us to define the numeraire, but the sum allows us to something else as interesting: the replicating portfolio. We don’t need to know what this is, but it is used in a particular kind of derivation for the fair value of an option on a risky asset in the Black-Scholes framework. We won’t be discussing that here but we will use it as motivation, namely: can we end up with the Black-Scholes partial differential equation using the Recipe for Pricing in the same way?
Let’s get right in to it.
We have our risky asset 

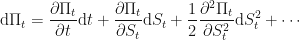
Let us substitute known quantities because we already know that,
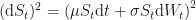
and this simplifies in to

because 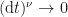
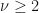

Substituting this in (and truncating the expansion at the second order) we get:
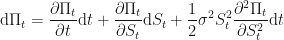
Let us now collect like terms and re-arrange:
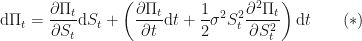
…and we get stuck.
We cannot proceed any further without making an assumption.
The assumption we want to make is to assume that this portfolio is self-financing i.e. that any purchase of a new asset must be funded by the sale of an old one. There can be no injection of cash or any other funds.
By assuming that this portfolio exists on its own and does not interact with any flow of money we can isolate and pin down the contributors to any infinitesimal change in value of the portfolio.
We say that the rate of change of the portfolio value 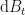
By making this assumption we actually relieve a degree of freedom from the system, because now the position sizes 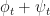
In symbols, this assumption alone allows us to write:

But we already know that 

Now we have have two equations 

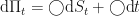
So, let us simply equate the terms…

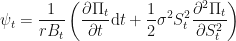
Now that we have the coefficients, we can substitute these in to the original additive portfolio:
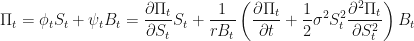
Expanding and re-arranging:
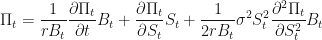
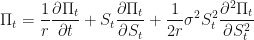

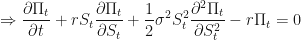
and we are done, because we end up with the Black-Scholes partial differential equation! One can now consult, say Shreve 4.5.14 and easily find solutions to this equation in terms of suitably scaled percentiles of cumulative normal distributions.
Conclusion
We have shown that the Black-Scholes partial differential equation is derivable from the Recipe of Pricing, i.e. through the complicated process of mixing a risky and a risk-free asset together, expanding via Taylor’s theorm, invoking Ito’s Lemma, and then making an assumption about a self-financing portfolio containing a fixed number of positions of varying amounts of the risky and risk-free asset. In this example, note that we did not need to change the measure or invoke Girsanov’s theorem.
Remarkably, two things vanished during this recipe:
- The source of randomness
- The risky asset’s drift
vanished as well! This means that the Black-Scholes PDE (and solutions of it) do not contain any mention of the drift of the risky asset. This is (and was) a huge deal.
It is remarkable that the value of the self-financing portfolio is completely independent of how fast (or slow) the risky asset grows (or shrinks) in value. The only parameter of the risky asset that remains is it’s volatility.
References
https://quant.stackexchange.com/questions/8247/why-drifts-are-not-in-the-black-scholes-formula
