
Ever wondered what a butterfly has to do with risk management?
In this article, we will take the reverse approach. We will start with some basic math, and work our way to the butterfly.
The Partial Derivative
Recall that the (first) partial derivative of a (real-valued) function of two variables 

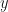
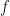


In effect, we have fixed the value in the second slot (to which the symbol
But what is the object on the right-hand side of the above equation?
Well, it is simply the derivative of the (real-valued) function of one variable 

If the function 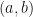
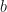


This derivative is geometrically a straight line, so it can be written down as well. Recall the equation of a straight line:

where 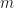

where 

Let us re-label the run component of this equation to something a little more traditional: 
So 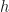
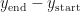
Pretty simply stuff.
So now we have:

But since we have already defined the one-variable function 
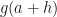
So now our gradient equation looks like this:

Let us say for convenience, that we always just run a distance of 1 unit; so we set 


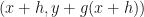
Wait! This is not a tangent line, because it necessarily intersects the original curve 
Thus in order for our equation for a straight line to become a tangent line we must introduce this concept of a limit as some variable (e.g. 
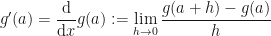
Now let us re-introduce that fixed, second variable. The ordinary derivative becomes the partial derivative:
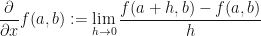
and that is as far as we can go without some extra tools.
Taylor’s Theorem
We would like to start discussing the second partial derivative, but we can’t without introducing the very useful tool known as Taylor’s theorem.
Taylor’s theorem says that if a real-valued function 


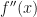

The more values we compute (the more derivatives we perform), the more accurate the approximation gets.
Let us only require second-order approximation, i.e. let us restrict ourselves to computing just the first and second ordinary derivatives. Then Taylor’s theorem says:

But recall that the definition of the run was 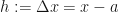
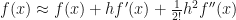
Let us use Taylor’s theorem twice: once for approximating 
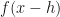

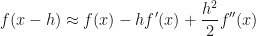
Adding these two together gives:
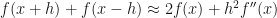
Rearranging:

And finally, this becomes an equality when we take the limit:
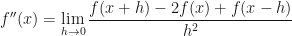
This becomes a partial derivative definition if we re-introduce our fixed, constant second variable:
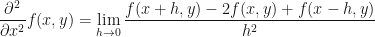
All pretty easy stuff. Right? In fact, already, the answer to our question is staring us in the face. Let us now see how we get from Taylor’s theorem to European option payoffs.
The Partial Derivative as an Option Strategy
Let us now look at this function

Recall that
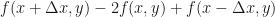
Now let us change notation a little to make this next concept clearer. Let us re-label 



This is looking like the payoff of four European call options!
In fact it is!
The full approxmation looks like this:
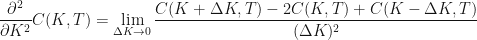
This says that the rate of rate of change of the price of an European call option with respect to the fixed, constant strike 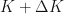

Amazing!
In other words, if you had a position consisting of just these four positions, then the portfolio value would be equal to 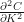
This specific kind of position is so important and fundamental it carries a special name: it is called a butterfly position.
So let us denote the value (at time 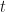
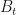
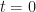


In other words, the value today of a Butterfly is equal to the discounted value of it’s second-order sensitivity to the centered strike
Butterfly and Second-order Partial Derivative
OK, so we have shown that there is a proportional relationship between the value of a butterfly position
But wait! This isn’t one of the traditional Greeks. The closest is Delta and Gamma but they are with respect to the underlying asset price 
Why is this? What can we use this for?
Well, Breeden & Litzenberger showed in 1978 that this partial derivative (and by what we have just showed, also the butterfly position) can be used to approximate the implied (risk-neutral) probability that the underlying asset price
But can’t you just do the same thing using volatility skew? Well, yes you can, but then you are subjecting yourself to Model Risk. This way, there is no model risk. This is all just supply-demand-arbitrage pricing. In fact, you mix this with the idea that for any time-

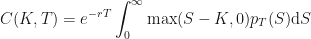
The Integral of a Maximum Function
With this knowledge in hand, we can re-arrange to get:

To evaluate the integral of the maximum function, recall the following little shortcut…

…because all values of
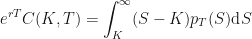
Now we need to differentiate both sides with respect to

Now, recall the Leibniz Integral Rule, written here for convenience:

And now we make the simple change of variable names: 





Remember, the (terminal) probability density
Since the derivative is defined in terms of a limit (as we covered initially in this blog), we can treat 
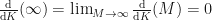
The second term in the Leibniz Integral is also zero. This time, it’s because 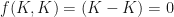

This just leaves the third and final term:

We can evaluate the partial differential under the integral sign (on the right-hand side) as follows:

Therefore:
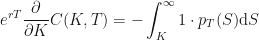
Finally, taking the same derivative again with respect to strike
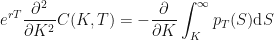


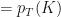
where the second equality above is given by the 2nd Fundamental Theorem of Calculus, and the third equality is due to the fact that all probability cumulative distribution functions reach 1 at infinity (by definition), and so the probability density there must vanish.
This is known as the Breeden-Litzenberger formula, named after Douglas T. Breeden and Robert H. Litzenberger for their Oct. 1978 paper (published in the Journal of Business, Vol. 51, No. 4, pp 621-651, under Prices of State-Contingent Claims Implicit in Option Prices.
Interpretation
The Breeden-Litzenburger result means that all you need in order to find a (risk-neutral & terminal) probability density 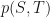

Indeed, call option prices contain distributional information about the risk-neutral measure 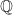
If you have an infinite number of call options at every possible strike, you can determine both the location and the shape of the risk-neutral probability density by calculating the 2nd order partial derivative of the prices w.r.t. the strike. Unfortunately, in order to do this (i.e. to get the price), you would need an implied volatility (or IV) at every point as well. And to calculate the IVs you need the price (using the same formula!).
Indeed, knowing a range of IVs across a range of strikes builds up the volatility smile which, in some way, also reflects the location and shape of the underlying risk-neutral probability density. But if we are to believe Black-Scholes, the underlying risk-neutral density is lognormal, so the IV should be constant across all strikes, and the smile should vanish.
What Breeden & Litzenberger did in 1978 was show how to infer the exact density given knowledge about the call prices and smile across a range of strikes.
Implementation
It is practically impossible to apply the Breeden-Litzenberger result since we cannot make infinitely narrow butterfly spreads, i.e. in practice, 
But where to interpolate?
Naively one might think of performing this interpolation in Price-Strike space, building up the hockey-stick picture. However, it is dangerously easy to accidentally allow arbitrage in to the picture this way. Another nice way to think about it is that since the price of an option is the dependent variable (i.e. the output) of a pricing model which has the usual Black-Scholes inputs: value of the underlying, strike, time to expiration, volatility, and interest rate.
It is much better to interpolate the independent variables (i.e. the inputs) because these should be smoother or better behaved that the output. In the extreme, the moneyness and the time to expiration are so well-behaved, because they are known quantities. In fact, the only degree of freedom that we really have here is the volatility. Which is why it is better to interpolate in the volatility-strike space (or the IV-K space).
I won’t be going in to this part of the implementation here, but allow me to re-direct you to a nice blog on this topic: https://reasonabledeviations.com/2020/10/10/option-implied-pdfs-2. Assuming, however, that we are done, we can convert the IV-K vol curve back to V-K space using the Black-Scholes equation, take the second partial derivative w.r.t. strike (numerically), to find all the points on the probability distribution function using the Breeden-Litzenberger equation.
This generates a butterfly-implied PDF of underlying price movements at maturity time
References
Prices of State-Contingent Claims Implicit in Option Prices.
https://reasonabledeviations.com/2020/10/10/option-implied-pdfs-2
