
Introduction
In this blog I want to talk about Markov Chains.
Pre-requisites
I will be roughly following this guide map:

As you can see, Markov chains exist within a probability space and consist of several mathematical objects enhanced by several properties. The main objects of interest are the graph, the enhanced stochastic process known as an adapted process, and, of course, the standard sample space, sigma-algebra, and probability measure. Properties that we will be dealing with are conditional probabilities, filtrations, the Markov property, states and graph edges.
Let’s assume that you’ve never seen nor heard of a Markov chain before, and go back one step to something a little more tangible: a state.
States & Graphs
A state is like a position but it’s a fairly abstract notion, and it can be a position of really just about any physical thing. In fact, in can be even more general than a position. A state is really just a set of numbers which describes something.
In information theory and computer science, a state as defined as some unique and recognisable collection of information. In mathematics and physics, a state is also a collection of information describing a point in space.
States are where you start when you want to understand Markov chains. So before we get in to Markov chains, let’s first learn how to combine states in to graphs.
Here is a state:

Looks pretty simple.
A single state sitting by itself like this is not very interesting. If we allow time to tick forward, however, then states can change.
Let us indicate this change by drawing another state with an edge connecting them to indicate that one state changes in to the other:
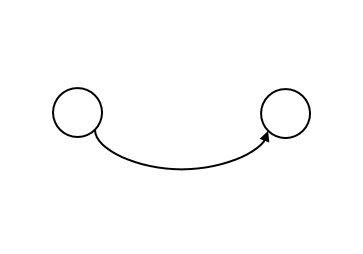
We can also indicate that the first state can be returned to from the second state with another arrow pointing back:
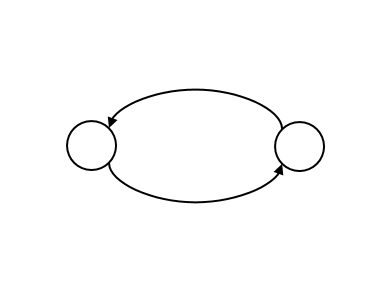
Let us now also draw in the possibility of remaining in the same state as time ticks by with little loops:

The above picture could represent a coin toss. Do you see? How about now?

This picture says that if the coin shows Heads, then there is a 50% probability that when the coin is flipped again (note: Heads, or 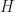

Converting in to a Matrix
We can always convert such graphs like the one of a coin above in to a matrix.
Simply take the number of states 



Then simply label the matrix entries like so:

Then map the pictures to the numbers:

which then becomes,

or, in proper matrix format

We denote this matrix by the letter 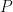



Obviously, since this matrix contains probabilities, each row of the transition matrix
So we have started with a basic concept of a state, joined them together with edges, and postulated that the passage of time reflects the notion of passage along an edge. Sounds pretty easy so far!
Linking Graphs to Markov Chains
The collection of all edges (transitions) and vertices (states) is a mathematical object called a graph.
We don’t have to get deep in to the theory of graphs to be able to define Markov chains, but we do need the definition of the Markov property, named after Andrey Markov (1856-1922).
But first, what sort of objects can inherit such a property?
Well, the sorts of things which can be “Markovian” are stochastic processes, in other words: collections, or even sequences of random variables 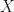
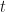

The Markov property states that the probability that the random variable, at time 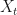



where 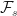


So here, we see that in order to define something as Markovian we need a concept of time, and we need to know how information is flowing from one point of time to the next.
This is why, whenever we refer to the Markov property, that we are careful to include the notion of adaptability, which, in itself, carries notions of sets of available information which are represented by 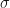
How special? Well, just special enough to model the flow of information.
Adapted stochastic processes cannot see in to the future, information does not flow backward in time. Moreover, one cannot define an adapted process without first defining precisely what set of possible events it is adapted to! So let’s do it!
We say a stochastic process 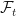
Consider the following diagram in a very rough context (this is not the rigorous definition, but should help visualise it):

Here, this particular arrangement of events (the circles) would indeed represent a filtration for the stochastic process 
Here is an example of a situation that is not a filtration:

Now, we don’t need to get in to the details of this. The main take away is that stochastic processes can possess the Markov property, and that this property is about the flow of information through the passage of time – represented by overlapping sets of data (as illustrated above).
The Markov property is a strong condition of this flow, because it says that the probability that the stochastic process moves to the next state depends only on where it currently is – it does not care about where it came from. And this is reflected in the illustration that the past, smaller circles are all contained with the present, large circle and so we do not need to consider them separately – we just consider the large circle.
We also say that Markov processes are memoryless.
Markov processes only care about the present and the future. The past is irrelevant.
Okay, so now that we know what the Markov property is, how do we link graphs of states (connected vertices) and the passage of time (represented by edges), to a stochastic process possessing the Markov property?
Well, we know that the changes of state (called transitions) are possible with graphs. And we know that on a graph, transitioning from one state to the next with the passage of time is done according to some probability (e.g. 50% in the coin toss example); and that probability can be packaged up neatly in to some square matrix.
If we indicate on our graph some starting position, and then allow that position to move around the graph according to the transition state probabilities, then after some amount of time

For example, consider the coin toss example, and let’s say we toss 5 times. The sequence that we observe is, say: Heads, Tails, Tails, Heads, Heads. The graph corresponding to this would be:

Mathematically, we represent this as a sequence of random variables:
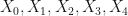
Each state 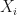

A Markov chain is thus a sequence of random variables 
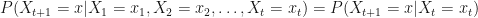
The Power of Markov Chains
Let us show the real power of a Markov chain. Basically, the Markov property allows us to reduce large products of complicated probabilities in to much simpler, shorter products.
Suppose we want to know the first 4 states of the process, i.e. we want to find this:

We use the Law of Total Probability to turn this in to the probability of first having 
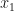
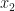
All of these ‘words’ are written mathematically as
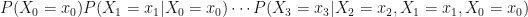
and, as you can see, this can get very long and very complicated indeed.
Introduce the Markov property!
Now, wherever you see a piece of the equation that looks like this:

it can easily be replaced by the much easier and shorter piece that looks like this:
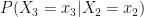
Thus,
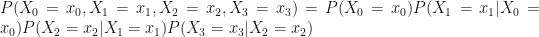
And we can go even further with notational convenience!
Since 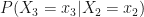

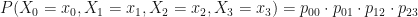
In other words, we just multiply the probabilities together!
Other Properties of Markov Chains
I now want to introduce three very important properties that Markov chains can possess: stationarity, irreducibility, and aperiodicity. For the purpose of this blog, and for brevity, I will assume you know what these properties are. If you don’t, may I suggest this introduction to them here [3]. Khan Academy also does a good job at introducing these three concepts here [1]. See these references at the end of the blog.
But very briefly, if we go back quickly to the transition matrix 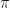
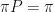
Well, if one does exist then we call it stationary. They can exist for some Markov chains, but not all. Note that the eigenvalue must be 1 for it to be stationary.
The stationary distribution of a Markov chain is perhaps the most difficult to understand. It can be thought of the histogram of the times a random particle transitions around the chain, visiting various nodes, some more often than others (depending, of course, on the transition probabilities). In a sense, the stationary distribution encodes the amount of time such a particle spends at each state if left to transition around for a very long time.
By this definition, if there are 
For example, with the coin toss Markov chain, there are two states (Heads and Tails) and so the stationary distribution is a vector of two numbers – namely, the amount of time the coin spends in each state. Since the coin is fair, one would assume that the coin spends an equal proportion of its time in each state and so the stationary distribution might look like this:

But these are probabilities, so an experiment of ten thousand coin flips might instead look like this:

Still adding up to a total of 1, as it must. So the stationary distribution, in this example, is a uniform distribution. And we can sample from the uniform distribution to reproduce an accurate simulation of a coin toss.
But this is probably one of the simplest Markov chains there is: only two states! Things get much more difficult as the chains grow in size. But one thing is for certain: if you act on the stationary distribution
But wait…couldn’t you just solve the eigenvalue-eigenvector problem as it stands!?
Sure, but when you have a large number of states, the vector
So how do we know, and I mean really know, for certain, that our Markov chain has one of these stationary distributions? And why do we even care?
Why Do We Care About Stationary?
Well, if it were stationary and we knew what the distribution of each 

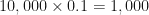
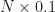

Thus, one of the attractive features of Markov chains is that we can often make them stationary, and this is a problem for linear algebra and not in part of this article. But for a great demonstration of how this is possible see reference [5].
The Limiting Distribution
To answer the “how do we know?” question, we know that from the Markov property we can reduce statements like “the probability that I’m in state 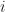
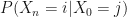
into a statement of probabilities from the transition matrix:
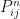
And now we know that from the Stationary property we can take limits, so that statements like
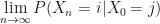
turn into statements like this:

but, of course, the stationary property dictates that this should equal

Interestingly, and most importantly, there is no assumption on the initial probability distribution, it’s the probability distribution of the chain that converges to the stationary distribution, regardless of the initial setting!
The Other Markov Chain Properties
Next: an irreducible Markov chain is basically one in which every single vertex can be reached from every single other vertex with a non-zero probability. This is a pretty easy one to imagine.
For example, the following Markov chain is irreducible because you can get from any state to any other state with a non-zero probability.

But, if we make a couple of small changes (in red), we can illustrate a reducible Markov chain:

Do you see why?
Because once we have reached the red state of no-return, we cannot get back to Region A from Region B:

This partition, or reduction of the whole Markov chain in to two smaller, disjointed chains represents a reduced Markov chain. A chain in which this cannot be done is thus irreducible – it cannot be reduced!
And finally, to understand an aperiodic Markov chain it is probably best to understand what it isn’t aperiodic! And by that I mean, a periodic Markov chain. Consider this Markov chain:

Periodic, or aperiodic?
It is most definitely a periodic Markov chain. Why? Because at any stage in the evolution of this chain I know exactly where I am going; I know with a 100% certainty what state I’ll be in, and further more: at any state I know exactly how long it will be before I return. Thus, I know my period, in this example it is 4 – just four time steps and I will return.
Now, what about the coin toss Markov chain?
The coin toss is indeed aperiodic. Simply because if I am at the Tails state, I only have a 50% chance of knowing where I will be next. I could be at Heads, or I could remain at Tails.
For more complicated Markov chains we need a much better definition for aperiodicity than just checking probabilities at each and every state. Think of the period of a state.
A state 
Ok, a bit confusing, but look at our example of a periodic Markov chain again. Let’s label this top state
We count 4. And this count is true no matter which state we choose and no matter which route we take.
But consider more complicated Markov chains. For a given state, you would need to test every single possible route from the state, out and back. Here is a route with a count of 5 for state

But here is another route with a count of 8:

Imagine we keep doing this: that is, finding different routes and counting how many steps it takes to get back to the start. After a while we end up with a long list of numbers like this:

Now, if the greatest common divisor of all these numbers is 1 (which usually means quite a good mix of different numbers!) then the state is said to be aperiodic. In a broad sense, the Markov chain is sufficiently mixed up.
But what if all your counts were something like this:

Well, then that state would be instead periodic, indeed with period 2. Since 2 (as well as 1, but 2 is bigger!) divides all the numbers in that set. Such a Markov chain is a little less mixed up and maybe has a little bit of a pattern inherent in it.
If every state of the Markov chain is aperiodic, then the whole chain is aperiodic.
Going back to the coin toss example, let’s say you pick the state Heads. Then the count the number of routes:

You can go from Heads back to Heads in literally any integer number of routes, including 1 – the route where you throw two Heads in a row. This set of all numbers definitely has GCD equal to 1 and hence the coin toss example is an aperiodic Markov chain.
Conclusion
So what is the point of all this?
Well, now something truly remarkable happens when a Markov chain is stationary (with stationary distribution
But more on that in the next blog!
References
[1] https://www.youtube.com/watch?v=tByUQbJdt14&ab_channel=mathematicalmonk
[2] https://www.youtube.com/watch?v=12eZWG0Z5gY&ab_channel=mathematicalmonk
[2] https://towardsdatascience.com/the-intuition-behind-markov-chains-713e6ec6ce92
For a really good introduction to Bayesian Inference and the Metropolis-Hastings algorithm (with an actual example in Python) take a look at this article:
A great demonstration of how to find stationary distributions for Markov chains:
[5] https://stephens999.github.io/fiveMinuteStats/stationary_distribution.html
